Windows软件
总结
概要列表
- cleanmypc:全方面电脑文件垃圾清理
- geek:最轻便且卸载最干净的卸载软件(直接下载解压后,双击 exe 文件即可使用,无需安装)
- snipaste:最牛逼的截屏软件,用过才知道
- uTools:各种小工具小插件,还是个微型的软件中心,只有想不到,没有它没有的。
- SpaceSniffer:对 C 盘等磁盘空间进行优化。能够可视化显示每个文件的占磁盘空间。
Windows
- 离线视频播放器 PotPlayer(官网下载)
- 录屏软件 Bandicam
- xshell,ssh终端连接
- Bandizip 压缩软件,推荐 7.0 之前的版本,免费且无广告
- listary,虽然 uTools 有基于 everything 的插件,但 listary 依然有用武之处
PDF专用
Drawboard PDF(已拥有,微软账号)
Drawboard 在 Win10 应用商店限时免费。Drawboard 更适合触摸屏和电磁笔手写,但是启动速度非常慢,文字渲染不够清晰。(支持手写的 PDF 阅读编辑器)
大名鼎鼎的 DRAWBOARD PDF,正价 88 元,有时候微软应用商店特价至 0 元,适合移动办公/SURFACE 平板人群使用。
万兴PDF专家(PDFelement),PDFelement功能齐全、极其易用、界面美观,是目前(2020年4月)用过的PDF软件中综合表现最好的。
嗨格式阅读器。小巧简洁,主打阅读。
uTools
非常好用!强烈推荐!!!!
Hello,各位小伙伴们好,又到周末了,给大家分享一款神器:『utools』。
官网及下载地址:https://u.tools/
uTools 是一个极简、插件化、跨平台的现代桌面软件。通过自由选配丰富的插件,打造你得心应手的工具集合。当你熟悉它后,能够为你节约大量时间,让你可以更加专注地改变世界。
utools 支持 Windows/Mac/Linux,
安装成功之后,可以通过快捷键『Alt+Space』,可以唤起 utools 窗口。
以下页面都是 mac 上截图,其他平台大同小异。

这个界面比较像 Alfred,刚开始没有安装任何插件,只能简单根据关键字查找系统中已安装的应用。

我们可以通过安装插件,扩展 『utools』的功能,提高我们的生产力。
uTools安装插件
相关插件都可以在插件中心安装,只需要在窗口输入插件,选择插件中心。
进入插件中心,选择安装相应的插件。
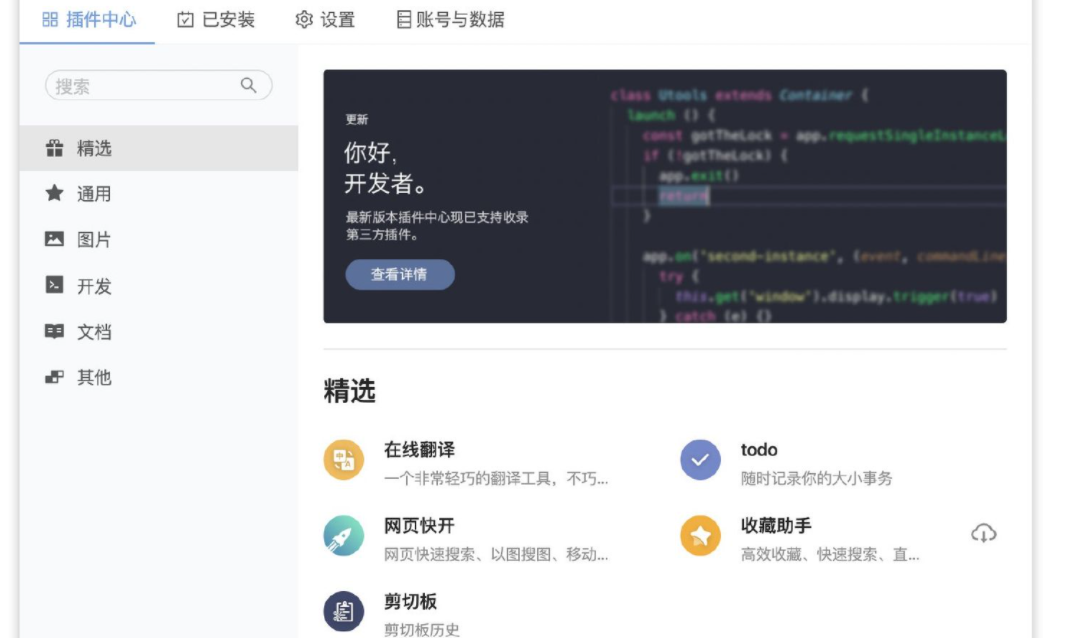
插件推荐
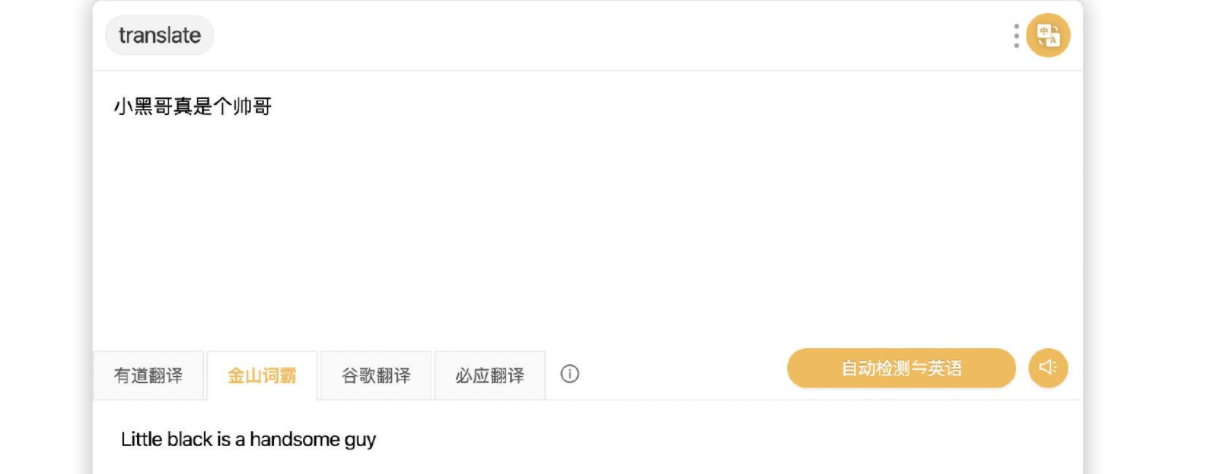
在线翻译
这个插件整合有道翻译、金山词霸、谷歌翻译、必应翻译。
关键字: translate/翻译
剪贴板历史
该插件可代替 Ditto
系统的剪贴板,只能查找最近一次的复制记录,这就比较麻烦。使用功能可以查找最近文本、图片、文件的复制记录,非常有用。
关键字:clipboard
斗图
这个功能么,聊天摸鱼神器,点击图片双击即可复制。
偷偷告诉你:很多骚表情都是可以从上面直接复制的。
关键字:doutu
JSON编辑器
通过这个插件,我们可以将复制过来的 Json 格式化,可以将 xml,yaml 转义成 json 。
关键字:json
编码小助手
日常开发经常遇到需要一些编码转化,比如 URL 编码。以前每次都需要谷歌搜个工具网页,现在直接使用这个插件就可以了。并且这个插件集合非常多转化小工具,
关键字:很多很多。。。。自己找吧!
base64
- 字符串 base64 编码
- base64 字符解码
- 图片 base64 编码
- 图片 base64 解码
- uTools 输入框自动识别 base64 字符串
data/unixtime/timestamp
- 时间格式转换
- 时间戳获取
- 标准时间
- uTools 输入框自动识别时间戳和 yyyy-MM-dd HH:mm:SS 格式时间
UUID/GUID
- 唯一 ID
Hash加密
- MD5
- SHA1
- SHA224
- SHA256
- SHA384
- SHA512
- 文件 HASH 加密
URL
- URL 编解码
常见文档(vue、Python等等)

可以快速查找 Linux 命令使用方法,这真是极好的。

人生进度条
件中心还有很多插件,小伙伴们可以自行查找。没找到想要的插件,小伙伴也考虑自己开发。
CleanMyPC
用起来非常爽,完全可以代替电脑管家等扫描垃圾的软件。
收费,但可破解。到网盘找压缩包
- 解压
- 安装 CleanMyPC.exe,安装完成后不要打开
- 复制 Patch.exe 到 CleanMyPC 的安装路径
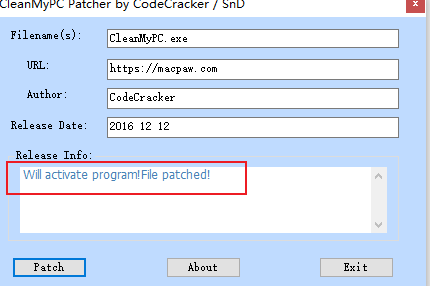
- 打开激活工具 Patch.exe,点击 Patch,完成。
如果弹出这个,说明 CleanMyPC 处于打开状态
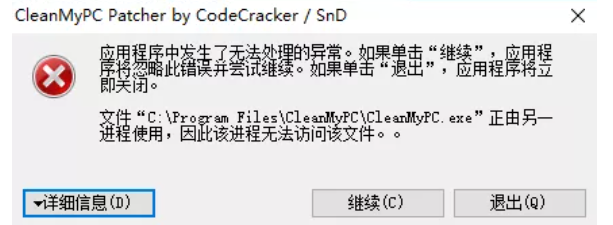
- 任务管理器,终止 “CleanMyPC NT Service” 进程,
- 系统服务,找到“CleanMyPC观察程序”服务,将服务停止,并将服务改为“手动”启动。
再打开 Patch.exe,点击 patch 激活。出现下方红框字样,说明激活成功:
SpaceSniffer
SpaceSniffer 是一款能够可视化分析磁盘空间占用情况的磁盘清理软件!免费,有用且可靠的,可以扫描Windows PC 上的文件。使用此工具,可以清楚地了解计算机硬盘中文件和文件夹的结构。为了检查磁盘空间,该程序使用 Treemap 可视化布局,该布局使您可以基于颜色感知大型文件和文件夹在设备上的位置。 由于此磁盘清洁器速度很快,因此您可以在几秒钟内清楚地了解整体情况。只需单击一下,SpaceSniffer 便会详细显示所选文件,包括大小,文件名,创建日期等。
下载地址和官网为:http://www.uderzo.it/main_products/space_sniffer/
下载后得到一个 zip 压缩包,直接解压后以“管理员”的身份打开 exe 文件

打开后,选择要分析的目录,就可以很快地得到该目录的磁盘空间占用情况:
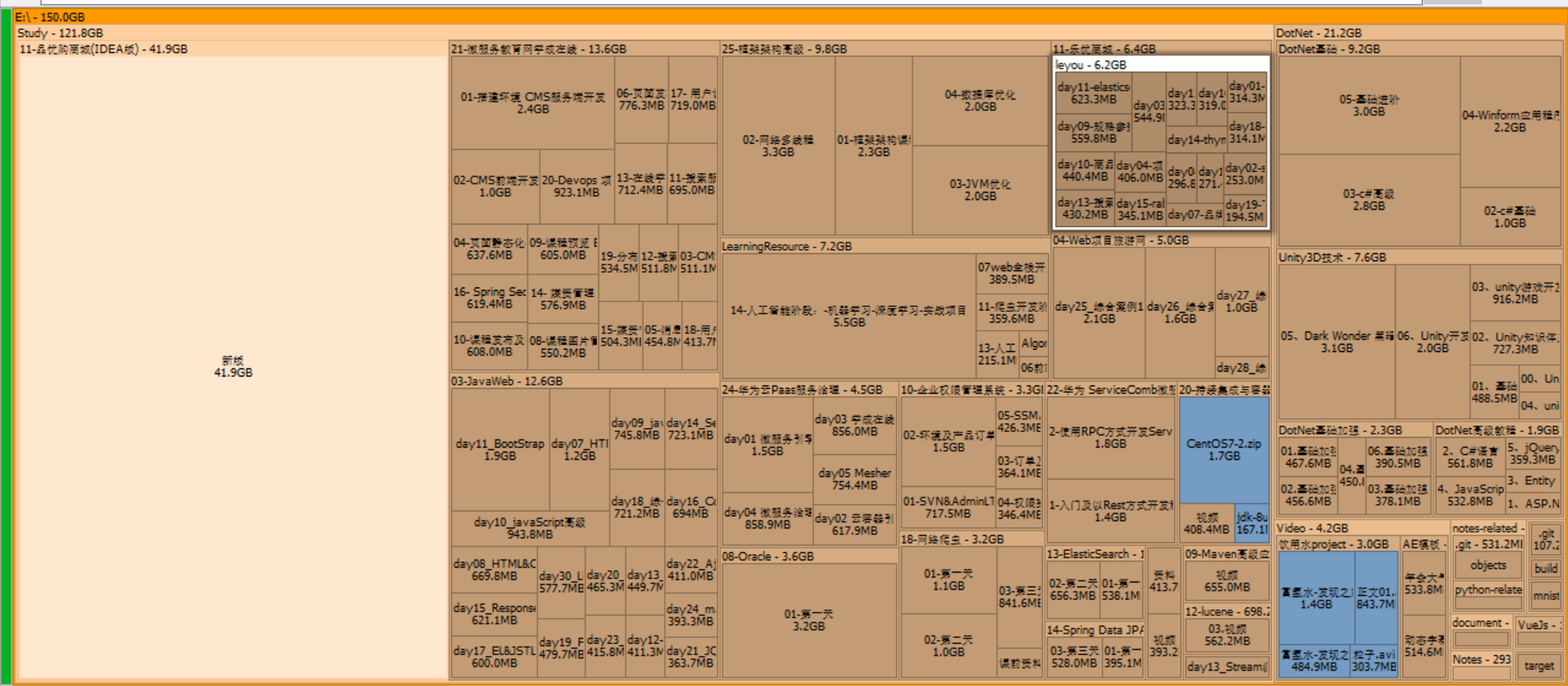
点击方格后,还会继续往下显示目录的磁盘占用情况,鼠标右键方格,则可以对该目录进行操作,打开、删除等等。
AVG
对电脑进行实时的性能监控
解锁猎人
解决文件无法删除的问题
天诺OCR
快速识别图片上的文字
USBSafelyRemove
解决 U盘 弹出失败问题
Recuva
恢复回收站删除的文件
录屏软件
Bandicam
做教程视频的时候是必须要用到录屏工具的,如果在 Windows 平台,那我的首选一定是这款来自韩国的Bandicam,因为它简单易用,功能强大,并且没有花哨多余的附加项,是一款纯粹的录屏软件。
OBS
录屏功能比 Bandicam 要丰富、强大,但使用起来比 Bandicam 略复杂。
总结
一般需求,使用 Bandicam 就足够了
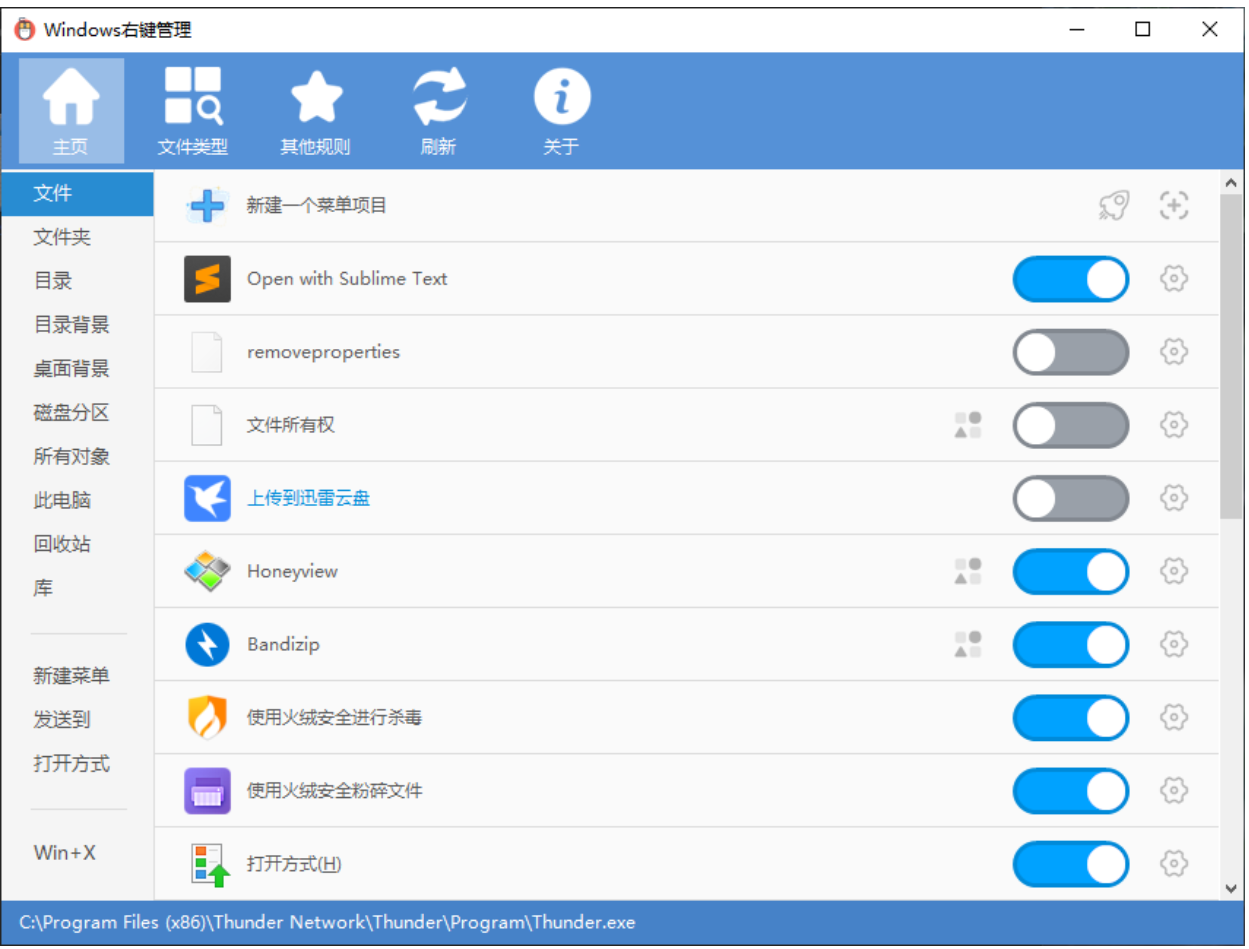
右键管理神器
https://github.com/BluePointLilac/ContextMenuManager
开源免费,非常方便地管理鼠标右键菜单,而不用自己去面对枯燥的注册表。